Real-time control of neural audio synthesis | Ella
In the video I am improvising with sound artist dedosmuertos, in La Villette, Paris. I am interacting in real time with the latent space representation of several models trained on raw audio using the RAVE neural network architecture (Caillon and Esling, 2021). To interact with the latent space, I am using a Gametrak controller. By means of Wekinator (Fiebrink and Cook, 2009), an application for supervised, interactive machine learning, I’m mapping the performance space to the latent space representation of the model.
MOTIVATION
I am very much interested in new ways of synthesizing and interacting with sound. Recent advances in neural audio synthesis systems, such as OpenAI’s Jukebox, Google Magenta’s DDSP, and IRCAM’s RAVE offer novel ways of generating sound in raw audio form from a model learned from audio directly.
Among those three architectures, DDSP and RAVE can be steered in real time at inference time, enabling a much wanted control of the sound generation processs.
DIRECT CONTROL OF THE LATENT SPACE
DDSP can be conditioned on pitch and level. RAVE can be conditioned on audio signal content (spectral characteristics and level). DDSP was designed to model monophonic sounds. RAVE was conceived to model full audio texture.
SOUND CORPORA AND NEURAL AUDIO MODELS
I have been training RAVE in several full audio texture corpora.
- Aventures Sonores (Corpus collected and assembled by sound artist Maar Colasso. It consists of poetry read by friends, conversations and historical recordingss of First Nations from South America, audio documents about space and time. 4.5 hours)
- vigliensoni. (All my music compiled into one corpus. 8h)
- Electro-percussive (Several albums of percussive music made mostly with electronic instruments. 15h)
- Acoustic-percussive (Several albums of percussive music made mostly with acoustic instruments. 19h)
- Electro-harmonic (Several albums of harmonic music made by electronic means. 22h)
- Acoustic-harmonic (Several albums of harmonic music made mostly by acoustic means. 33h)
- Waterlab. (Corpus recorded and assembled by sound artist Maar Colasso. 4h)
- Archivo sonoro Museo de la memoria y derechos humanos (120h)
- Historical recordings (e.g., discourses, manifestations)
- Music (e.g., from radio shows)
- Audio letters
CONTROLLING GENERATIVE MODELS WITH INTERACTIVE MACHINE LEARNING
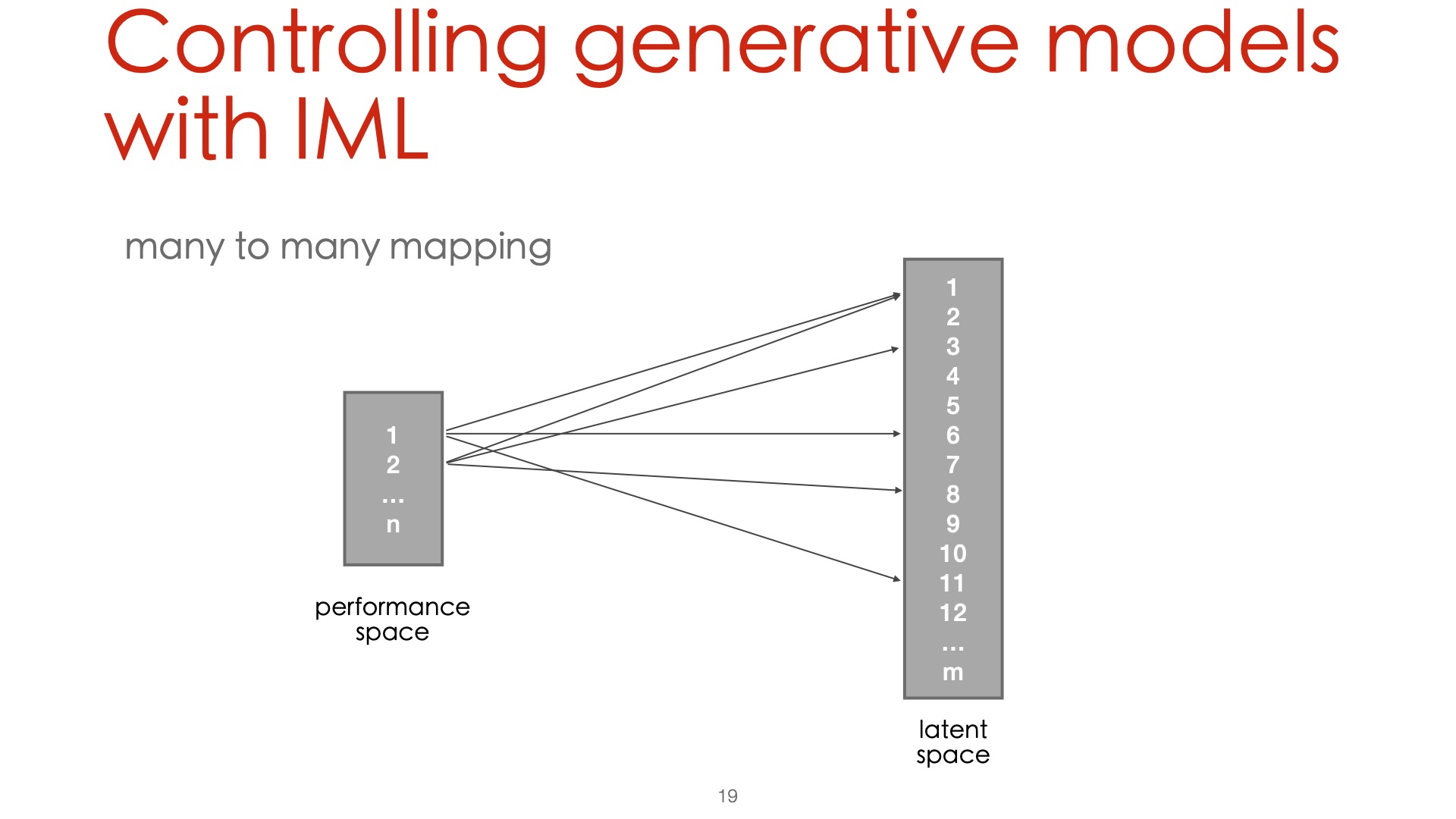
An interactive machine learning environment (such as Wekinator), allows to easily map the low-dimensional peformance space to the highly dimensional neural audio model space.
THOUGHTS
- Small datasets are enough to learn useful models
- Latent space representations can lead to unexpected, surprising places
- Non-linearity allows to find new ways of looking at the creative process
- Recent generative systems can be steered in realtime
- Contemporary AI systems can support musical creativity
- New tools should imply new music